Restore Data from Backup
The main factors to consider when restoring Redwood Server from a backup are:
- Consistency of the restoration across the entire landscape.
- Reconciliation of processes or chains that are running or were scheduled between the backup and restore times.
Consistency
As data is stored in many locations in the system landscape, consistency of that data can be an issue. For instance, process information like Status is stored in the repository, while its output is stored on disk. If the backup of the database is older than the disk then there will be output files on disk that are not linked to processes, while if the database is newer than the disk then the process may be Completed with links to files that do not exist.
Consistency problems can be reduced by:
- Frequent backups.
- Performing backups when no processes or chains are running.
Reconciliation
Even if you have a consistent restore, it is possible that processes or chains were scheduled to run (and in fact ran) between the time of the backup, the time of the failure and the time that the restore occurred. This means that a database restore may not contain correct data for this period.
The timeline below illustrates the possibilities:
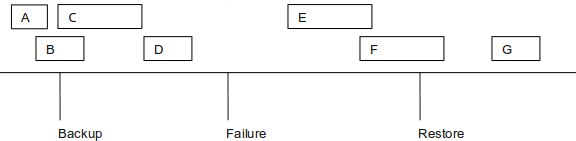
The different processes start and finish (or are scheduled to) at different times relative to the backup, failure and restore, and hence require reconciliation strategies:
| Type | Reconciliation |
|---|---|
| A | None required - captured completely by backup. Status and output will both be correct. |
| B | process will appear as Running and change status when the process server is started. May resolve automatically for: SAP jobs that still exist on the managed system. Platform agent jobs that are still running. Otherwise the status will be set to unknown. |
| C | Will appear as Scheduled even though it started and finished. Can be left to re-run automatically if there are no side-effects. If it is critical that the process is only run once, manual resolution is required. May only have partial files present. |
| D | Ran and had its status updated, but information was lost because it was not part of the backup. Resolution for status is the same as C, files will be complete. |
| E & F | These processes will be in status Scheduled, and not have been started, they will start when the system is restored. |
| G | These processes are unaffected. |
In all cases, if the process started before the failure and the system where the process was running was not affected by the failure, then output will exist and be correct.
Reconciliation problems can be reduced by:
- Performing backups when no processes are running - this means that there will be no processes of type B.
- Holding queues while the backup is performed, or setting process servers not to start on startup - this will prevent processes of type E and F from starting automatically when the restore completes.
Frequent backups - this will reduce the number of processes of type C, D, E and F and hence reduce the amount of reconciliation work.